
(15min)本文包含诊断、评测、学情画像、自适应推荐等相关内容,阅读时间约15分钟
引言
在消费互联网中,AI发挥了极大的作用,比如百度的搜索引擎、阿里的商品推荐引擎、腾讯的社交关系挖掘、甚至于抖音本身就是基于AI(基于推荐)的基础来构建的。随着产业互联网的发展,云以及其相关的AI技术开始深入到各个行业当中,比如AI和监控、和交通、和医疗等行业的结合,都对行业产生了深刻的影响。本文主要介绍AI和教育行业的结合。
从古到今,在教育领域都有一个共同的愿望叫做“因材施教”,中国古代的诸子百家,实际上就是现在的小班教学、师徒教学,本质上是个性化的教学;从西方诞生大学制度以来,开始有专业分工、开始有学科教育,本质上也是向个性化教学的转变。
当我们把目光聚焦在我国当前的K12教育,目前的大班课、近乎一致的教材和教学进度实际上是将教学标准化,当然这和我们教学资源的不均、通识教育的普及、过独木桥的现状等非常多的因素是相关的。一般意义来讲,标准化的教学意味着公平,但可能真正的“因材施教”对于每个个体而言才是更大意义上的公平。
随着慕课平台的发展以及教学内容的极大丰富,实际上大家拥有了个性化的选择学习内容的机会。国外比如knewton等机构,很早就在开展了个性化学习:自适应学习,他们根据学生的不同的学习状态、学习水平、学习进度,给学生推荐最适合的学习内容,来达到更有效率的学习的目的。国内也有很多的公司开始在自适应学习方面做了很多落地的尝试,比如讯飞、比如松鼠AI,都是将AI和教育结合,再结合具体的场景,进行了非常多的落地实践:比如讯飞的个性化学习机、比如松鼠AI赋能教培机构的能力体系、比如个性化学习手册、比如学情报告等等。那本文争取相对系统性的介绍一下自适应学习。
什么是自适应学习?
其实科学的定义自适应学习还蛮难的,那我们用通俗的一句话来定义,就是:在合适的时间给合适的学生推荐合适的教学资源,以实现精准教学。其整体流程大概是这样:
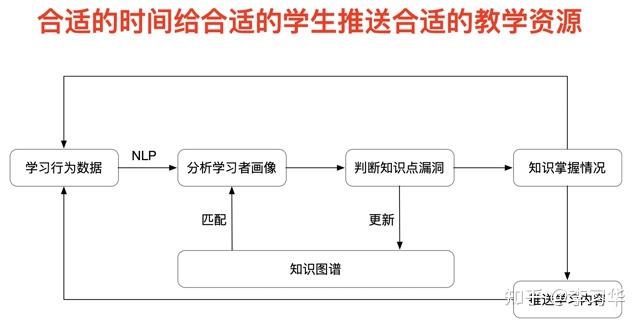

前置条件:
教、学过程的数字化,对于AI技术的落地而言,没有数据是万万不能的。因此如果期望自适应教育能够落地并产生价值,就一定需要对教学过程的数字化、在线化(理论上数字化越彻底越好,但限于实际情况,部分的数字化是必须的);因此就数字化而言网课、慕课平台、在线教育平台有天然的优势。
基本概念:
诊断:通过学生的答题行为数据,分析出学生的能力水平、知识点漏洞、题目的难度区分度数据等,是相对静态的。比如通过全校学生的考试情况来获得题目难度和学生等级等
评测:就某一学习范围,通过出题及学生答题的反馈分析出学生的薄弱知识点的过程,是相对动态的,且包含了出题过程。也就是说出题策略和发现学生薄弱知识点的算法通常是一体的
知识追踪(学情画像):是一个完全的动态过程,通过学生的答题对错情况,实时计算学生对于知识点的掌握度
教学资源:和教学相关的题目、讲义、视频课程、微课等
相似题:在举一反三的背景下,两个题目的知识点、难度、考察要点、解题思路等接近
知识图谱(知识点图谱):和学科相关的知识点所构成的树状结构的图谱,包含知识点之间的父子关系、前置后置依赖关系等
学习路径规划:一般情况下,我们都是按照教材的顺序进行学习的,但实际上有时候前后两个章节的知识点并无前后置关系(无需学会a再学习b),因此可以根据需求自动的规划最优的最适合某一层级学生的知识点的学习次序,就是学习路径规划
自动组卷:给定考察范围、试卷难度区分度等,通过算法从题库筛选符合要求的题目形成试卷
有了前面的基本概念,我们接下来看看自适应学习的实现路径和基本算法。
一、必要性
在数字化、在线化、个性化的前提下,自适应学习或许是在海量的教学内容和资源中,对学生来说最有效的学习方式之一。就和信息、商品爆炸的情况下,推荐引擎是最有效率的方式一样。也因为目前的教学无论是老师、学生还是家长层面,都有很多无法克服的问题,如下图:
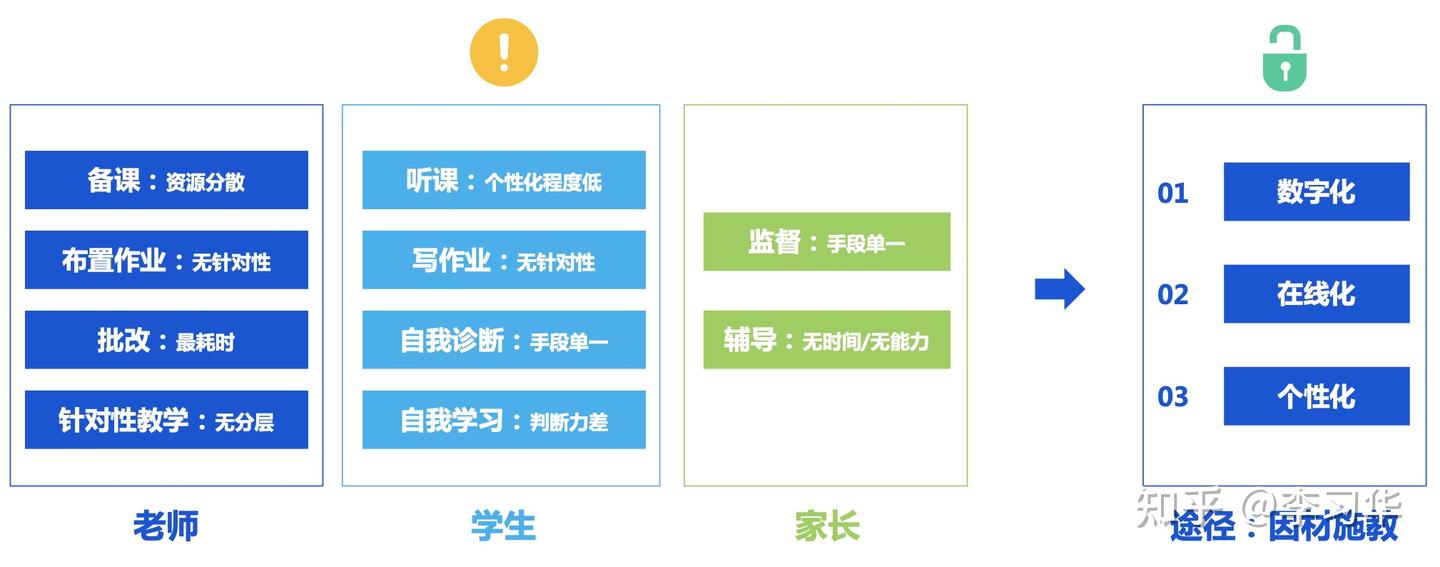
当然,这里要说明几个点:
- 自适应推荐引擎的实现逻辑和目前信息、商品基于偏好的实现逻辑是不一致的;
- 自适应推荐引擎需要有明确的(近乎苛刻的要求)可解释性;
- 学习效率可能不一定是学习最重要的需求(也可能是读书百遍,其意自现…);
前面也提到,教育的个性化和公平性可能是冲突的;非数字化场景下,最好的个性化教育是一对一,老师时刻关注学生的学习情况并给予及时的反馈,但在优质教育资源本就匮乏的时代,个性化教育的反面实际上牺牲了公平性。既要保证教育的个性化(因材施教),又要解决教育资源匮乏的问题,可能通过AI能力来辅助老师以提高教学的效率,把老师从部分繁重、重复的工作(如作业批改)中解放出来,是实现教育个性化和公平性的路径之一;也或许把AI变成最懂学生的那个“老师”,让更多的人实现更普惠的个性化,就是更大意义上的公平。
二、如何做诊断
认知诊断不是一个新的概念,在教育心理学领域已有数十年的发展。简单来说,认知诊断就是“诊断”被试内部的“认知加工过程”;对学生来说,以前我们只知道学生的分数,来判断学生的学习水平,却不知道学生到底好在哪儿差在哪儿;有了认知诊断,能帮助我们了解学生学到了什么、怎么学到的、会不会做题等等。
其中,项目反应理论(Item Response Theory,IRT)和DINA(Deterministic Input Noisy And)模型是最经典的两类工作。IRT模型中,学生的能力值通过theta参数来刻画,题目的难度、区分度则通过b和a参数刻画,反应函数中一个能力值为theta的学生答对难度b、区分度a的题目的概率如下:

基于IRT模型,当有大量的学生作答数据时,我们可以通过EM算法估计出学生的能力值theta参数以及题目的难度b、区分度a等参数;那如果作答数据的题目都是和某一个知识点相关,我们就能够得到这个学生针对这个知识点的能力值(掌握度)水平。
而DINA模型中,每个学生和试题则使用一个离散的向量表示,同时联合试题知识点关联矩阵-Q矩阵和学生答题情况矩阵-X矩阵对学生进行建模,并引入slip(学生在掌握某知识点但是答错的概率)和guess(学生未掌握某知识点但是答对的概率)参数进行建模;模型简单,且参数有较强的可解释性,一般使用极大似然的方式进行估计。关于DINA模型,可以参考:
DINA模型解析与实现_门前大桥下-CSDN博客_dina模型blog.csdn.net/orangesuan/article/details/85789903
近期,认知诊断模型也有了新的发展,比如NeuralCD模型,通过神经网络来学习学生和题目之间的复杂的交互作用,该框架有较高的准确度和可解释性。其结构图如下:
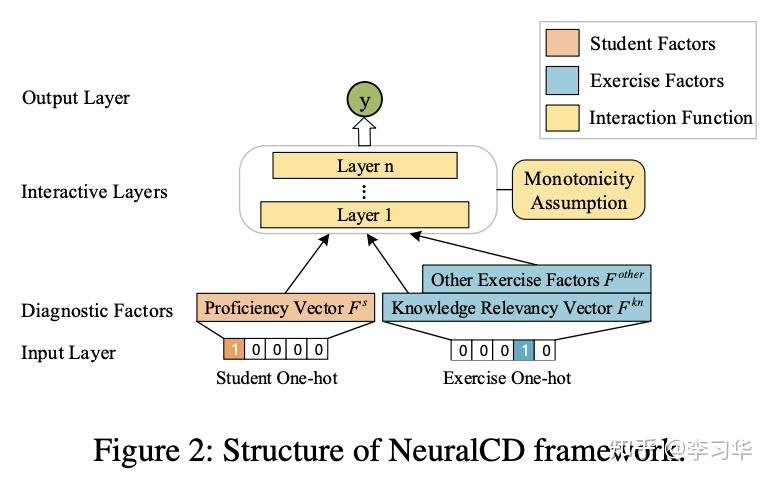
想详细了解NeuralCD的相关内容,请参考:
NeuralCD–智能教育系统中的神经认知诊断_研行笔录的博客-CSDN博客blog.csdn.net/qq_36317312/article/details/109990747
综合起来,诊断要求我们已经拥有较多的答题记录,进而分析出学生的能力参数或者是薄弱点,从统计意义讲,比较适合学生、班级、年级等共性薄弱问题的发现。
三、如何做测评
我们有生活经验的自适应测评是什么呢?GRE的机考自适应,是以section为单位的自适应,也就是说你第一个section的做题情况(对错、得分率等)会决定你第二个section的题目的难度,所以很多时候,如果你发现给你考试的题目越来越简单,你就需要留意了。
极端的,如果一个学生有足够多的时间,足够的耐心,我们把考试范围内所有知识点的题目从易到难都让学生做一遍,那么我们就能准确的把握学生的薄弱知识点,但显然,实践中这是不可行的;所以我们退而求其次的做法是通过尽量少的题目,来发现学生的薄弱知识点,同时保证一定的评测精度;我们来看一个相对合理的方式是怎样的?

参考上图,假设我们不清楚学生的初始能力值,我们可以通过第一轮出题(中等难度)后学生的答题对错情况来决定下一轮推荐题目的难度水平,直到学生的能力值稳定在一个水平(比如我们可以通过极大似然估计的方式迭代能力值参数),我们就认为完成了对于学生的评测。
当然,在实际的产品中,我们还需要关注评测时知识点的覆盖率、知识点权重、尽量少的评测题目、尽量准的评测精度等多个因素,我们来看下面这个框架:
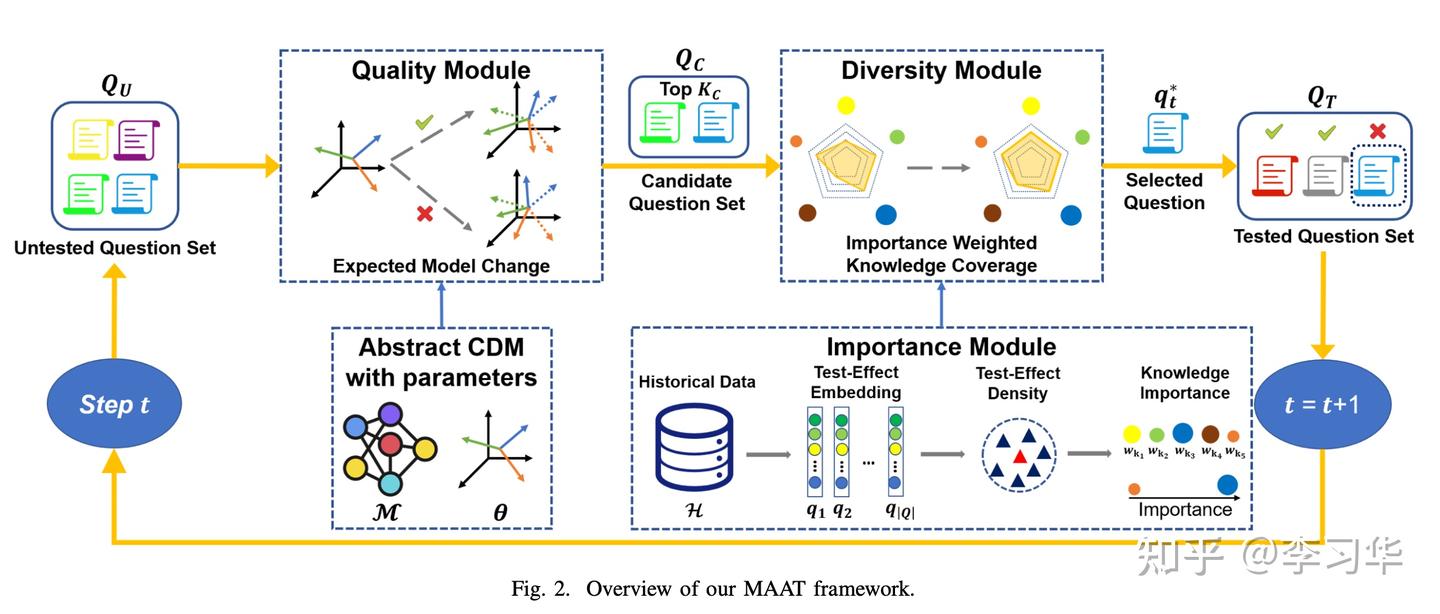
基于上面框架,我简单介绍一下其大致思路:
- 选择用于评测的候选题目时,估计学生答对题目a的概率为p,假设本轮选择题目a进行评测,那么根据预测的概率p(离散化为答对答错1/0)的情况来更新学生的CDM参数(比如知识点掌握度、比如能力值等),选择CDM参数变化最大的一组题目作为候选题(信息熵最大);
- 在候选题中,需要选择让整个评测过程能够最大化其知识点覆盖多样性的题目,参考图中的Diversity Module,但不能一味的只追求多样性,还需要考虑知识点的权重;
- 知识点权重代表选择那些重要的知识点,并同时保证多样性;参考图中Importance Module,重要性模块是通过某个知识点下面,题目的集中程度决定的,也就是说如果整个题库中的题目和某个知识点下面的题目越接近,则这个知识点越重要;
通过以上方法,我们选到了信息熵最大、同时保证知识点重要性和多样性的题目用于评测。那如何保证评估的精度呢?以上框架最大的好处就在于可以灵活替换其中的CDM模块,没有耦合,我们可以通过持续迭代获得效果最好的认知诊断(or学情画像)方案,来提升评测的精度。有了评测模块,我们就能够更快更准的发现学生的薄弱点并进行针对性的教学推荐。需要强调的是,评测有时候也会有不同的目的,所以出题策略在MAAT模型框架下,可能需要根据使用场景进行调整。
四、如何做学情画像
学情画像是自适应教育中最重要的模块,甚至没有之一;是我们动态跟踪学生对于知识点的掌握程度、学生能力水平的变化等的基础模型,然后才能基于学情画像对学生进行个性化的教学资源、题目等的推荐。那如何做学情画像呢?其实认知诊断是学情画像的基础模型,我们可以对学生的某一知识点进行建模,获得其认知诊断的参数,也可以通过类似NerualCD类型的认知诊断模型隐式的学到知识点的掌握度。随着矩阵分解以及深度学习模型的演进,学情画像演变出了另外一类方案,基于答题对错预测模型的学情画像引擎,我们通过预测学生能否答对某个知识点的典型题目来间接的、评估学生对于知识点的掌握度,答题对错模型的一般范式如下:

提供学生信息、题目信息以及学生和题目的交互历史行为等,进而预测学生答对其他题目的概率;答题对错预测模型的演进可以参考下图:
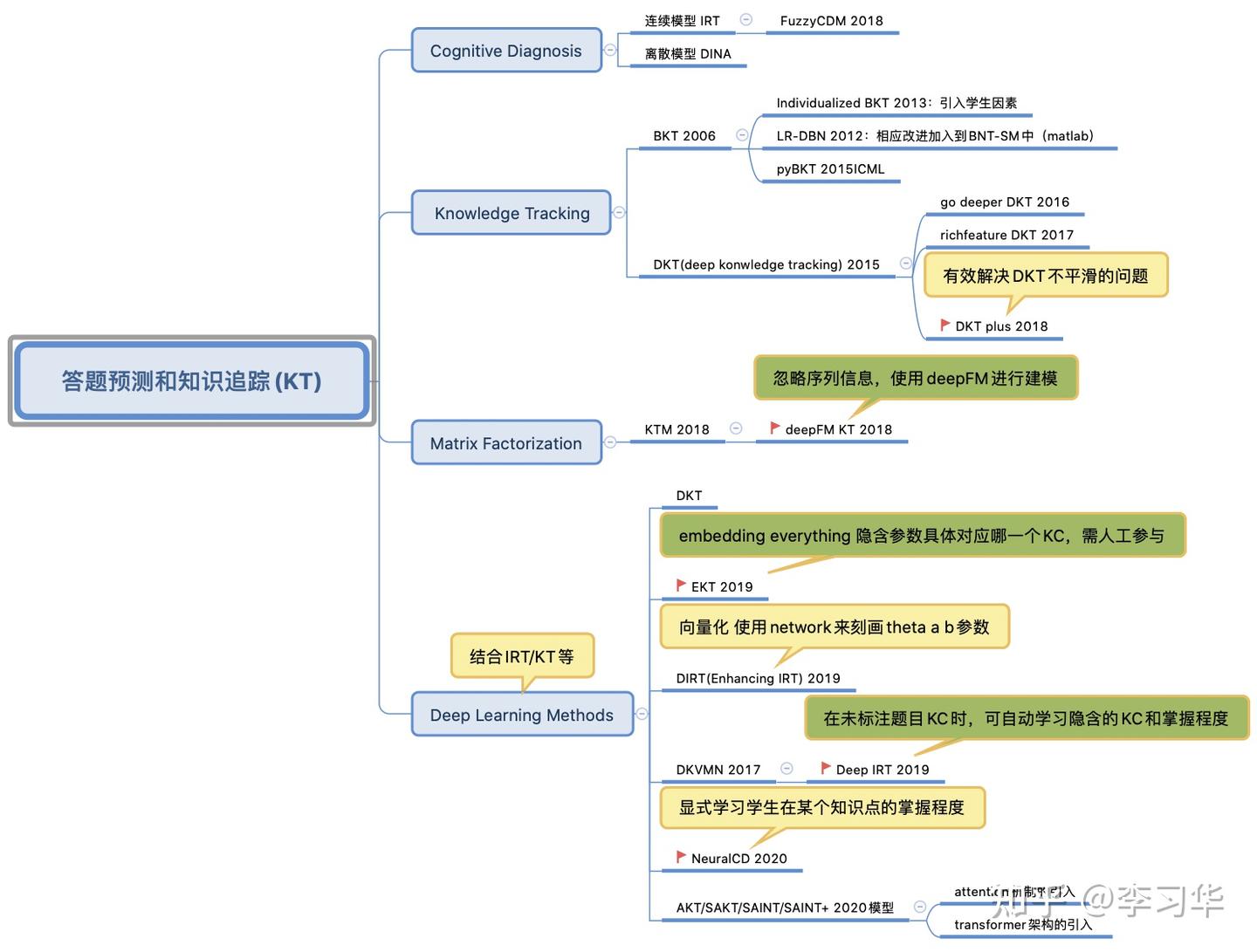
这里,我们不去介绍答题对错预测某一个具体的模型(主要是太多了),而是从整体上给出其发展脉络。
- 早期:基于参数化的模型,无论是IRT模型、双参数IRT模型、DINA模型,都是在尝试参数化题目(难度、区分度、猜对的概率等)以及参数化学生(能力值、能力向量、知识点掌握度),然后通过公式(如项目反应理论)、模型去预测学生答对题目的概率;他的好处是在于直观,但无法充分挖掘数据中隐含的特征;
- 中期:基于矩阵分解的模型,这类模型是在数据量增加的场景下诞生的,忽略掉人为设计的可能影响答题对错的参数,通过MF/FM等方式直接学习数据中隐藏的pattern,这类模型显然忽略了答题对错之间的序的关系,哪怕是在参数中引入和序有关的特征,但依旧不完美;但胜在能够从数据中学习到隐含的特征,有利于模型的泛化;
- 当前:随着深度学习的普及,我们可以向量化一切的对象,进而通过向量之间的距离来刻画学生vs.学生、题目vs.题目、学生vs.题目之间的“相似度”,来进一步扩展模型的泛化能力;尤其是近期,基于transformer的语言模型很好的刻画了输入的序的问题,基于attention机制的深度学习模型,很好的刻画了不同特征之间交互的问题,使得深度学习模型的效果得到了进一步的提升。
实际应用中,我们需要根据当前的业务规模、业务需求、复杂度等诸多因素对答题对错模型进行选择;那假设我们有了一个非常准的答题对错预测模型(这个模型本质上可以通过类似广告点击率CTR预估模型的后验方式来进行评估,因为我们能够从一个在线答题的场景获得丰富的学生的作答数据),那我们应该怎样来获得学生对于知识点的掌握度呢?
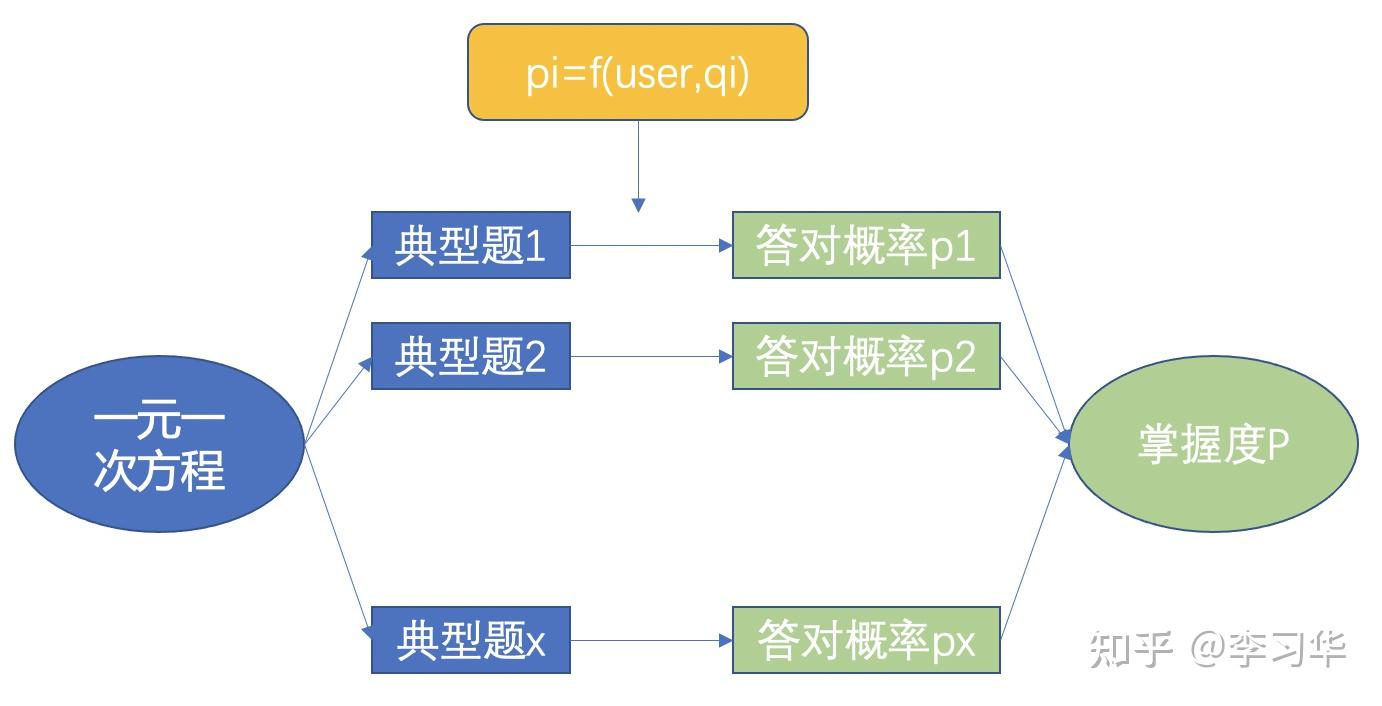
如图,假设某一个知识点有x个典型题目,那么我们通过答题对错预测模型(黄色部分)能够预测出某一个user答对这些题目的概率,进而加权求和得到用户对于这个知识点的掌握度;这个框架有非常好的可扩展性和持续迭代的空间,我们可以通过持续可衡量的指标迭代答题对错预测模型,进而获得更好的对于学生学情画像的刻画,也可以通过更准确的衡量知识点掌握度的典型题目的增删,获得更直观的掌握度的理解。
即便如此,目前的学情画像引擎依旧存在较多的优化的空间,比如:
- 答题对错模型的可解释性问题,由于深度学习模型可解释性差的原因,如何让学生或者老师接受预测出来的答题对错的概率,本身就很难;
- 冷启动问题,比如我们拥有的对某个学生或者某个题目的数据非常少甚至是没有的情况下,如果进行刻画,此时答题对错预测模型显然精度会下降很多,如何在这种情况下获得稳定的学情画像,值得考量;
- 脏数据问题,比如某个学生答错某一个题目显然不是因为他不会,可能是因为题目太简单而随便答;也可能是因为抄了同桌的答案,而非真的学会了某个知识点,这些都会导致模型的刻画有偏;
- 数据缺失问题,限于当前的教学模式的情况,我们很难获得学生更全面的学习行为数据,比如听了某一堂课,考了某一份试卷,买了某一本教辅书籍等,所以我们只能获得学生的部分行为数据,而这部分数据本身就是有偏的,要想在这种情况下获得对学生全面的认识,还是蛮难的。
五、如何做教育的个性化推荐
在介绍教育的个性化推荐之前,我们先来看一般的推荐系统,本质上是根据用户的偏好进行推荐,偏爱运动装备,则推荐更多的运动装备的商品。而教育推荐系统不一样,用户消费某一个知识点下面的题目、讲义多,可能意味这这个知识点用户已经掌握了,因此教育推荐系统本质上是基于“漏洞”的推荐,而发现漏洞就是学情画像引擎;同时,教育推荐系统对于可解释性的追求是近乎苛刻的,老师在给学生指导的时候可能考虑了学生的学习习惯、性格、心理学等诸多的因素,而显然目前的教育推荐系统还达不到。二者的区别参考下图:
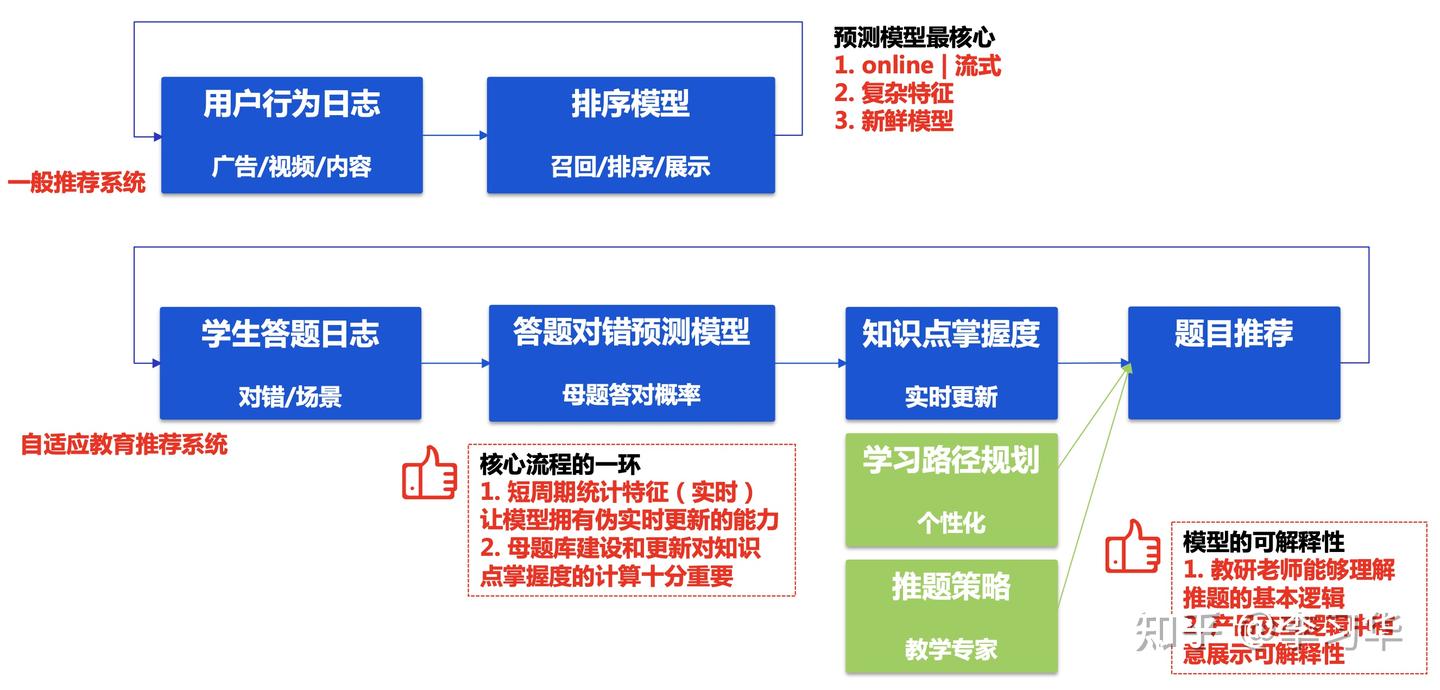
做一个理想的假设,我们对于某一份讲义、题目、微课有非常精准全面的刻画,比如适合什么层次的学生、精确的知识点(甚至是解题方法、解题思路等)、预估时长、适合的场景、是否风趣、是否有挑战性等等,那么只要我们有对学生“漏洞”的准确刻画,对学生层次、场景、学习习惯等的准确的刻画,那么就能够做到精准的推荐。因此,教育推荐的核心不在于推荐算法,而在于对推荐的内容的精准刻画和对于学生“漏洞”的精准刻画(学情画像引擎解决),那么如何通过AI来辅助对内容的精准刻画就变得极其重要,但很可能,短期内这本应该是一个依赖教研或老师的人力占主导的工作。
这里,我们介绍三个教育的个性化推荐的范式:
基于相似题的推荐(举一反三)
很显然,在我们学习的过程中,我们会经常使用举一反三来强化学习某些内容,也或者是通过举一反三来持续巩固自己不会的题目,基于相似题推荐的难点在于如何寻找相似题。
基于薄弱点的推荐(补齐短板)
通过评测和学情画像,我们能够动态的、清晰的知道学生的薄弱知识点,那我们就可以借助于教学资源精准的标签体系进行推荐,其本质在于如何保证教学资源的标签精准以及对薄弱点的刻画精准,以及需要判断二者是否需要使用相同的刻画体系。(比如我们会刻画学生的某个知识点的某种解题思路没有掌握好,那是否需要匹配相应的教学资源也是某个知识点的某个解题思路)
基于学生能力层级的推荐(协同推荐)
基于学生能力层级的推荐实际上是某种程度的分层推荐或者协同推荐,比如奥数班的学生就推荐最难的内容、最需要探索的内容等等,而普通的学生,可能掌握好书本的内容就非常重要。这种范式的推荐核心在于分层的合理性以及对分层有挑战时的应对方式,毕竟我们不能限制一个当前成绩差但提高意愿强烈或未来潜力很大的学生不去接触奥数。
总结起来,教育的个性化推荐底层是对于内容的精准刻画,上层是基于不同应用场景的不同的推荐范式,那有没有类似推荐系统的直接通过召回+排序的框架获得推荐列表的方法,值得探索。另外,如何衡量和评估推荐的好坏也是一个问题,不同于商品推荐引擎,我们显然不能通过推荐的题目的答题正确率来衡量,毕竟多推荐简单题就能提高答题正确率(而商品推荐,我们可以通过推荐商品所产生的商业价值做评估)。
写在最后
诚然,自适应学习可能是实现“因材施教”的路径,但如何评价自适应学习的效果,如何证明自适应学习相比目前的其他教学模式有优越性,是很难的一个问题。
短期,我们可能能够通过两个班级学生的得分情况来对比?
中期,我们可能能够通过两所学校的升学率来对比?
长期呢?我们可能能够通过两个群体所养成的学习习惯来对比?
很显然,都不现实,也不科学;两种教育模式本就不应该有高低之分;十年树木、百年树人,或许承认教育模式本就存在不完美,而通过很多人努力去“改善”教育的尝试的过程本就应该值得鼓励,而非结果。
后记:自适应学习的目的是帮助学生更有效率的学会需要掌握的内容,但需要掌握的内容是谁决定的呢?是教材?是考试的指挥棒?我们的理想愿望是期待当学生更有效率的学会需要掌握的内容之后,能够有时间去发现兴趣;去学习自己感兴趣的内容、而不是规定的内容;去思考、去丈量世界…,如果达成,善莫大焉!
参考文献:
- Personalized E-learning System Using Item Response Theory.
- DINA model and parameter estimation: A didactic.
- Interpretable Cognitive Diagnosis with Neural Network.
- Fuzzy Cognitive Diagnosis for Modelling Examinee Performance.
- Neural Cognitive Diagnosis for Intelligent Education Systems.
- Dynamic Key-Value Memory Networks for Knowledge Tracing.
- Enhancing Item Response Theory for Cognitive Diagnosis.
- Deep Knowledge Tracing.
- Deep Factorization Machines for Knowledge Tracing.
- EKT: Exercise-aware Knowledge Tracing for Student Performance Prediction.
- Quality meets Diversity: A Model-Agnostic Framework for Computerized Adaptive Testing.
- Context-Aware Attentive Knowledge Tracing.
- RKT : Relation-Aware Self-Attention for Knowledge Tracing.
- Towards an Appropriate Query, Key, and Value Computation for Knowledge Tracing.
- SAINT+: Integrating Temporal Features for EdNet Correctness Prediction.
主题测试文章,只做测试使用。发布者:qinglinet,转转请注明出处:https://www.qlw.net/uncategorized/%e8%87%aa%e9%80%82%e5%ba%94%e5%ad%a6%e4%b9%a0%e4%b9%8b%e6%88%91%e8%a7%81%e6%95%99%e8%82%b2ai.html